Publicado: 2024-03-10 (actualizado 2024-10-04)
Etiquetas: Mastodon, Proyectos, Python
Hace unas semanas se me ocurrió cambiar la configuración de mi cuenta de Mastodon para que borrase automáticamente las publicaciones al cabo de unos meses y así ganar algo más de privacidad. El problema es que varios miles de mensajes iban a desaparecer para siempre si activaba la opción de borrado automático y a mí me gusta almacenar todo así que intenté descargarme todo el contenido usando la opción que proporciona la interfaz web de la red social. Por desgracia, la opción de exportar contenido no funciona en mi instancia y la administración no parece que lo pueda solucionar.
Tras la desilusión inicial decidí exportar mis datos yo mismo utilizando la API de Mastodon. El año pasado creé mi propio bot en Python por lo que escribir un script que baje todos los mensajes no debería ser muy difícil.
Nota del 2024-10-04: finalmente arreglaron los problemas para descargar los datos pero yo sigo ejecutando el script de este artículo una vez al mes para archivar mis comentario.
Para utilizar la API de Mastodon es necesario obtener un token de acceso para nuestro programa o script. Tan simple como, desde la interfaz web de la instancia, ir a preferencias > Desarrollo y allí pulsar el botón Nueva aplicación.
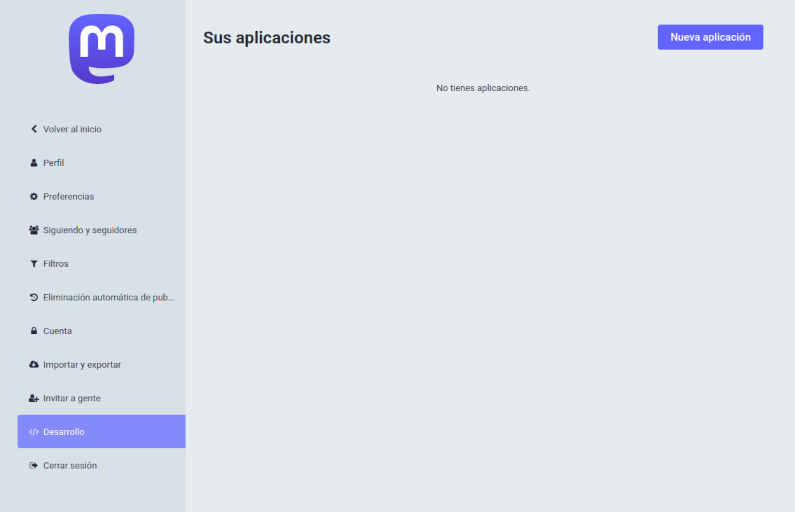
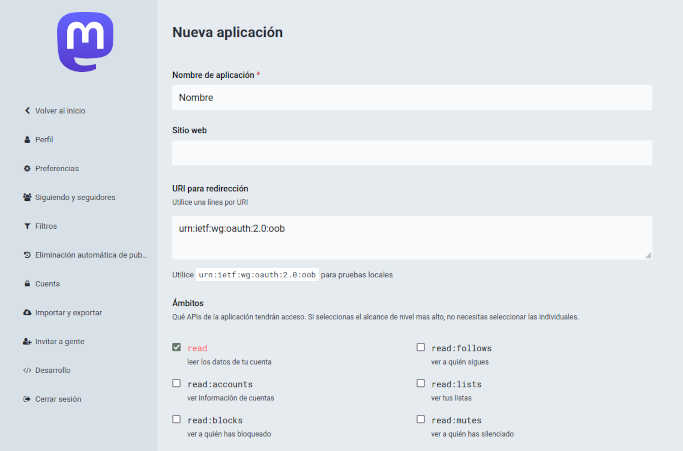
Hay que dar un nombre a la aplicación, el resto de campos se dejan tal y como están.
Cuando se termine de crear la aplicación cargará una página con 3 cadenas de texto: "Id de la aplicación", "Secreto" y "Tu token de acceso". No hay que darle estos valores a nadie porque sería como decirles nuestra contraseña. Por eso en la imagen siguiente aparecen pixelados.
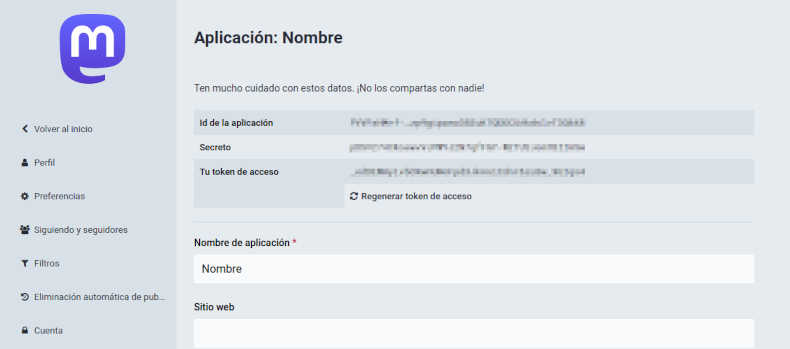
Lo único que necesitamos es el token de acceso. El resto es irrelevante en estos momentos.
Ahora a por el código. Creé un entorno virtual Python con el módulo Mastodon.py.
python3 -m venv python_env
source python_env/bin/activate
pip install Mastodon.py
Empecé el script iniciando sesión en mi instancia. Recuerda poner el token de acceso que te han dado al crear la aplicación y la URL de tu instancia.
Para crear un cliente solo necesitamos una instancia de la clase Mastodon. En caso de error, por ejemplo si el token de acceso es incorrecto, el script termina mostrando un mensaje que nos da pistas de lo que ha ocurrido. Tras iniciar sesión obtengo la información de mi usuario y muestro el nombre por pantalla simplemente para saber que todo ha ido bien.
from mastodon import Mastodon
client = Mastodon(access_token='aksjdhfjklasdfjklasjkldfhklashdf', api_base_url='https://example.com')
me = client.me()
print('username', me.username)
print('id', me.id)
Ejecutando este código debería mostrar por pantalla tu nombre de usuario y un número bastante largo que es tu id de usuario. No necesitamos hacer nada con estos datos. Es solo para probar que podemos enviar peticiones a la API de Mastodon.
Me costó un poco de encontrar pero al final di con la función que necesitaba: account_statuses devuelve las publicaciones de una cuenta concreta. La única complejidad es que es una llamada paginada. Es decir, va devolviendo resultados poco a poco y hay que llamarla varias veces para obtener todas las publicaciones.
Por lo que he visto, si pasas el último id recibido te devuelve en el argumento max_id las siguientes publicaciones así que hay que usar un bucle. Los otros argumentos son el id de la cuenta de la que queremos obtener las publicaciones (en mi caso yo mismo así que uso me.id) y la cantidad de resultados que queremos (limit). Al menos en mi instancia parece que la API devuelve 40 resultados como mucho así que no sé si vale la pena poner un valor más alto.
# Primera llamada sin max_id
statuses = client.account_statuses(id=me.id, limit=50)
data = []
while statuses:
data.extend(statuses)
lastId = None
# Guardar todas las publicaciones en el directorio data/
for s in statuses:
lastId = s.id
with open(f'data/{lastId}.json', 'w') as fout:
json.dump(s, fout, default=str, indent=True)
# Solicita las siguientes publicaciones usando lastId
time.sleep(10)
statuses = client.account_statuses(id=me.id, limit=50, max_id=lastId)
He puesto un time.sleep(10) para que descanse 10 segundos antes de volver a pedir publicaciones. No quiero saturar el servidor de la instancia.
Además de las publicaciones también quería descargar todas las imágenes que había subido así que tuve que investigar cómo conseguirlas. Parece que no hay ninguna llamada de la API que devuelva las imágenes sino que las propias publicaciones incluyen la URL de las imágenes adjuntas: cada una de las tiene una lista llamada media_attachments. Si esa lista contiene algún elemento quiere decir que hay ficheros adjuntos.
He añadido al bucle anterior el siguiente código. Básicamente mira la lista, para cada elemento busca la URL del fichero y se descarga el fichero utilizando el módulo requests.
if s.media_attachments:
# Hay uno o más ficheros multimedia adjuntos a la publicación
for m in s.media_attachments:
imgData = requests.get(m.url).content
imgFile = os.path.basename(m.url)
with open(f'data/{m.id}_{imgFile}', 'wb') as fout:
fout.write(imgData)
Por curiosidad también añadí un par de variables para contar el número de veces que habían marcado como favorita una de mis publicaciones y también el número de veces que habían sido compartidas. El único detalle a tener en cuenta es que hay que comprobar si la publicación fue creada por uno mismo. Si no es posible que cuente favoritos de publicaciones ajenas por ejemplo si hemos hecho reblogs.
No tiene mucho misterio. Cada publicación tiene los campos favourites_count y reblogs_count que te dan la información por lo que solo hay que agregar los valores.
if s.account.id == me.id:
reblogs_count += s.reblogs_count
favourites_count += s.favourites_count
Este es el script final que he usado para bajarme todo mi contenido por si a alguien le resulta útil. Tardó casi media hora en descargarse todas mis publicaciones de Mastodon.
import json, os.path. requests, time
from mastodon import Mastodon
client = Mastodon(access_token='aksjdhfjklasdfjklasjkldfhklashdf', api_base_url='https://example.com')
me = client.me()
print('username', me.username)
print('id', me.id)
data = []
statuses = client.account_statuses(id=me.id, limit=50)
reblogs_count = 0
favourites_count = 0
while statuses:
data.extend(statuses)
lastId = None
for s in statuses:
lastId = s.id
with open(f'data/{lastId}.json', 'w') as fout:
json.dump(s, fout, default=str, indent=True)
if s.media_attachments:
# Has images or video
for m in s.media_attachments:
imgData = requests.get(m.url).content
imgFile = os.path.basename(m.url)
with open(f'data/{m.id}_{imgFile}', 'wb') as fout:
fout.write(imgData)
if s.account.id == me.id:
reblogs_count += s.reblogs_count
favourites_count += s.favourites_count
time.sleep(10)
statuses = client.account_statuses(id=me.id, limit=50, max_id=lastId)
print('total', len(data))
print('reblogs_count', reblogs_count)
print('favourites_count', favourites_count)