Publicado: 2026-05-13
Etiquetas: IA, Proyectos, Python
Buenos días, tardes o noches:
Hace dos semanas escribí un artículo explicando que había mejorado el código del bot de Telegram. Entre los cambios que hice mencioné que había actualizado al modelo gpt-5.4-nano de OpenAI. Pues apenas unos días después ya vi que el cambio en el modelo había sido para peor: con mucha más frecuencia de antes, la IA devolvía el texto sin traducir, a veces tal cual, a veces cambiando alguna palabra.
El modelo anterior tenía tendencia a no traducir mensajes de una persona en concreto. Creemos que es porque su estilo de escribir era muy coloquial y en algunos casos gramaticalmente incorrecto. Ya comenté en su día que cada vez que cambiaba a un modelo más nuevo y supuestamente mejor, el bot funcionaba peor y sigue ocurriendo. Ahora se deja sin traducir textos de otras personas.
Por curiosidad, acabo de ejecutar git grep "model=" $(git rev-list --all) para buscar todos los modelos que he usado estos años. Aquí está la lista
Tras 4o volvimos a usar 3.5-turbo porque funcionaba mejor pero ambos fueron retirados ya de la API así que tuvimos que actualizar a 5-nano. Me parece indignante que un prompt con 4 frases que funcionaba perfectamente con un GPT de 2023 se le atraganta a modelos de 2026 que ocupan 100 o 1000 veces más. Supuestamente estos nuevos modelos son genios capaces de resolver problemas matemáticos ultra complicados. ¿Y no son capaces de seguir unas simples instructiones? Sospecho que los benchmarks esos que usan para evaluar a las IA están trucadísimos.
Por si fuera un prejuicio mío y yo estuviera equivocado, decidí hacer una prueba más científica. Me propuse evaluar el modelo y el prompt. Para ello instalé en mi servidor casero Langfuse que es una plataforma de observabilidad para modelos de lenguaje. Muy resumido: cada vez que haces una llamada un LLM se guarda el input, output y un montón de metadatos como el coste, tokens, etc. Luego lo muestra en una UI bonita y allí puedes etiquetar las muestras. Marcas las que sean incorrectas. Probar distintas versiones de prompts, etc.
Integré el bot con Langfuse y llevo unos días recogiendo muestras. Cuando consiga 100 o así las etiquetaré con los idiomas y me pondré a evaluar distintos modelos para así saber a ciencia cierta cuál funciona mejor. Aprovecharé para probar también mi IA local y si tiene un resultado medio decente empezaré a usarla y por fin dejaremos OpenAI de lado.
Como Langfuse permite representar visualmente todo el flujo de la ejecución, me animé a hacer un cambio que quería haber hecho hace mucho tiempo: en vez de tener un prompt que básicamente dice "si el texto está en idioma A, tradúcelo a B y viceversa" pasé a tener dos fases. Primero se identifica el idioma y una vez ya lo sabemos usamos un prompt más sencillo. Ahora para cada mensaje procesado podemos ver su traza en Langfuse.
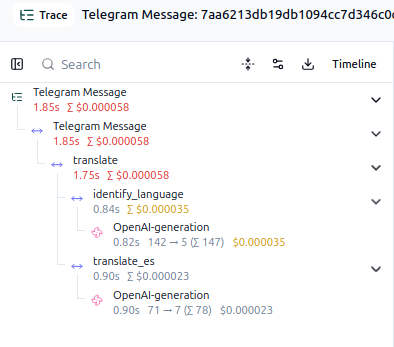
Un problema que he encontrado al instalar Langfuse en el servidor es que usa bastantes recursos y supongo que cuando termine con esta prueba lo eliminaré.